Τις περισσότερες φορές, όταν πρέπει να αποκλείσετε την πρόσβαση SeekportBot ή άλλα crawl bots με μια ιστοσελίδα, οι λόγοι είναι απλοί. Το web spider κάνει πάρα πολλές προσβάσεις σε σύντομο χρονικό διάστημα και ζητά τους πόρους του διακομιστή web ή προέρχεται από μια μηχανή αναζήτησης στην οποία δεν θέλετε να ευρετηριαστεί ο ιστότοπός σας.
Είναι πολύ ωφέλιμο για έναν ιστότοπο που επισκέπτεται ο γrawέπεσα πάνω του. Αυτές οι αράχνες ιστού έχουν σχεδιαστεί για να εξερευνούν, να επεξεργάζονται και να ευρετηριάζουν το περιεχόμενο των ιστοσελίδων στις μηχανές αναζήτησης. Η Google και η Bing χρησιμοποιούν τέτοια γrawέπεσα πάνω του. Ωστόσο, υπάρχουν και μηχανές αναζήτησης που χρησιμοποιούν ρομπότ για τη συλλογή δεδομένων από ιστοσελίδες. Seekport είναι μία από αυτές τις μηχανές αναζήτησης, η οποία χρησιμοποιεί crawτο SeekportBot ler για την ευρετηρίαση ιστοσελίδων. Δυστυχώς, μερικές φορές το χρησιμοποιεί υπερβολικά και δημιουργεί περιττή κίνηση.
Καμπίνα
Τι είναι το SeekportBot;
SeekportBot είναι μια web crawler που αναπτύχθηκε από την εταιρεία Seekport, που εδρεύει στη Γερμανία (αλλά χρησιμοποιεί IP από πολλές χώρες, συμπεριλαμβανομένης της Φινλανδίας). Αυτό το bot χρησιμοποιείται για την ανίχνευση και την ευρετηρίαση ιστοτόπων, ώστε να μπορούν να εμφανίζονται στα αποτελέσματα των μηχανών αναζήτησης. Seekport. Μια μη λειτουργική μηχανή αναζήτησης, απ' όσο μπορώ να καταλάβω. Τουλάχιστον, δεν μου έδωσε κανένα αποτέλεσμα για καμία φράση-κλειδί.
SeekportBot χρήσεις user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Πώς να αποκλείσετε την πρόσβαση στο SeekportBot ή άλλο crawΈκανα κλικ σε έναν ιστότοπο
Εάν έχετε καταλήξει στο συμπέρασμα ότι αυτή η αράχνη ιστού ή άλλη, δεν είναι απαραίτητο να σαρώσετε ολόκληρο τον ιστότοπό σας και να κάνετε περιττή κίνηση στον διακομιστή ιστού, έχετε πολλές μεθόδους με τις οποίες μπορείτε να αποκλείσετε την πρόσβασή τους.
Τείχος προστασίας σε επίπεδο διακομιστή ιστού
Είναι εφαρμογές τείχους προστασίας open-source που μπορεί να εγκατασταθεί σε λειτουργικά συστήματα Linux και μπορεί να ρυθμιστεί ώστε να αποκλείει την κυκλοφορία βάσει πολλών κριτηρίων. Διεύθυνση IP, τοποθεσία, θύρες, πρωτόκολλα ή παράγοντας χρήστη.
APF (Advanced Policy Firewall) είναι ένα τέτοιο λογισμικό μέσω του οποίου μπορείτε να αποκλείσετε ανεπιθύμητα bots, σε επίπεδο διακομιστή.
Επειδή το SeekportBot και άλλα web spider χρησιμοποιούν πολλαπλά μπλοκ IP, ο πιο αποτελεσματικός κανόνας αποκλεισμού βασίζεται στο "user agent". Έτσι, εάν θέλετε να αποκλείσετε την πρόσβαση SeekportBot μέσω APF, το μόνο που έχετε να κάνετε είναι να συνδεθείτε στον διακομιστή web μέσω SSHκαι προσθέστε τον κανόνα φίλτρου στο αρχείο διαμόρφωσης.
1. Ανοίξτε το αρχείο διαμόρφωσης με nano (ή άλλου εκδότη).
sudo nano /etc/apf/conf.apf2. Αναζητήστε τη γραμμή που ξεκινά με «IG_TCP_CPORTS” και προσθέστε τον παράγοντα χρήστη που θέλετε να αποκλείσετε στο τέλος αυτής της γραμμής, ακολουθούμενο από κόμμα. Για παράδειγμα, εάν θέλετε να αποκλείσετε user agent "SeekportBot", η γραμμή πρέπει να μοιάζει με αυτό:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Αποθηκεύστε το αρχείο και επανεκκινήστε την υπηρεσία APF.
sudo systemctl restart apf.serviceΗ πρόσβαση "SeekportBot" θα αποκλειστεί.
Φίλτρο web crawls με τη βοήθεια του Cloudflare – Αποκλεισμός πρόσβασης του SeekportBot
Με τη βοήθεια του Cloudflare, μου φαίνεται η πιο ασφαλής και βολική μέθοδος με την οποία μπορείτε να περιορίσετε την πρόσβαση ορισμένων bots σε έναν ιστότοπο με διάφορους τρόπους. Η μέθοδος που χρησιμοποίησα και στην υπόθεση SeekportBot για να φιλτράρετε την επισκεψιμότητα σε ένα ηλεκτρονικό κατάστημα.
Αν υποθέσουμε ότι έχετε ήδη προσθέσει τον ιστότοπο στο Cloudflare και ότι οι υπηρεσίες DNS είναι ενεργοποιημένες (δηλαδή, η επισκεψιμότητα στον ιστότοπο περνά μέσω του Cloudflare), ακολουθήστε τα παρακάτω βήματα:
1. Ανοίξτε τον λογαριασμό σας στο Clouflare και μεταβείτε στον ιστότοπο στον οποίο θέλετε να περιορίσετε την πρόσβαση.
2. Μεταβείτε στο: Security → WAF και προσθέστε έναν νέο κανόνα. Create rule.
3. Επιλέξτε ένα όνομα για τον νέο κανόνα, Field: User Agent - Operator: Contains - Value: SeekportBot (ή άλλο όνομα ρομπότ) – Choose action: Block - Deploy.
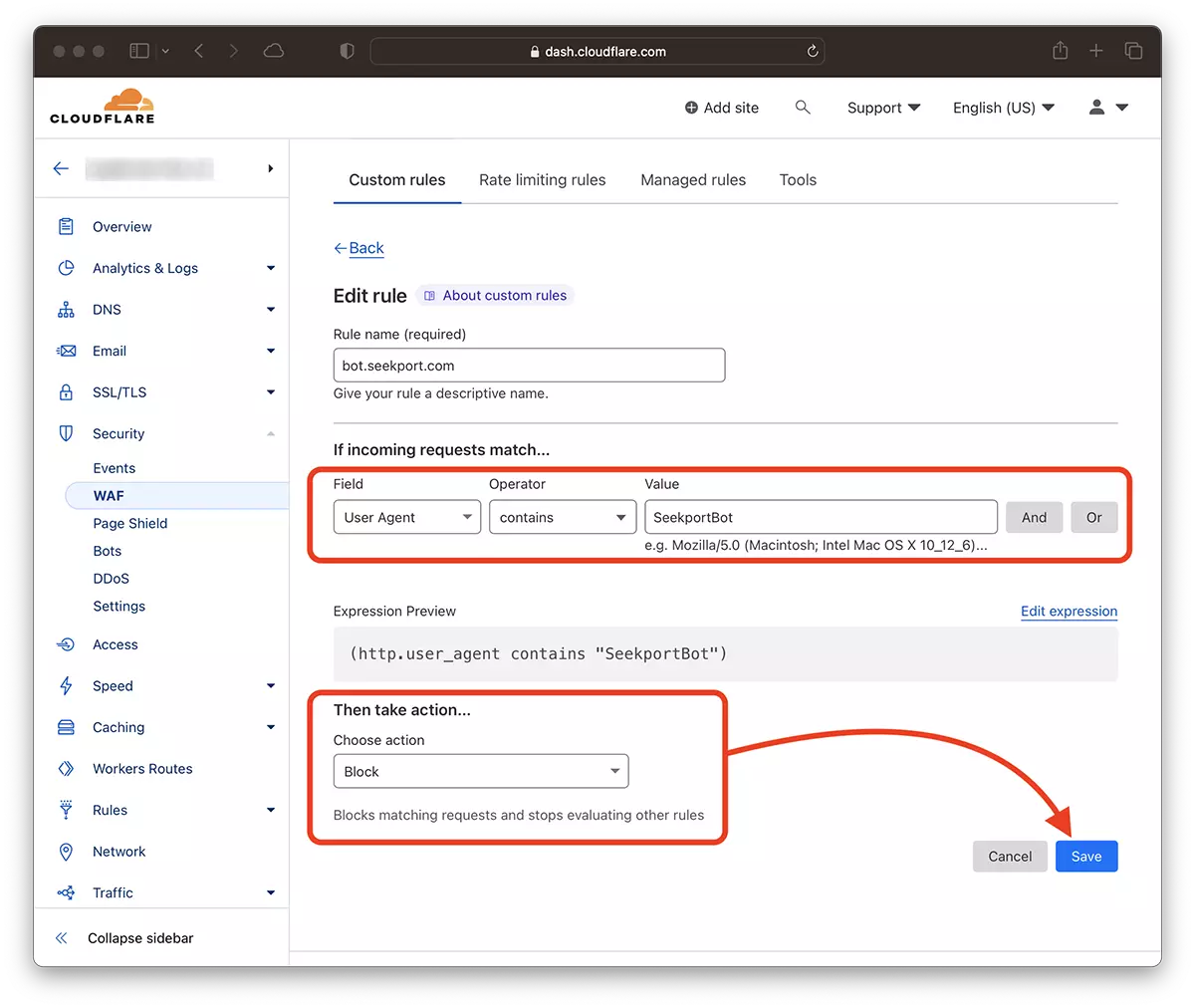
Σε λίγα δευτερόλεπτα ο νέος κανόνας WAF (Web Application Firewall) αρχίζει να ισχύει.
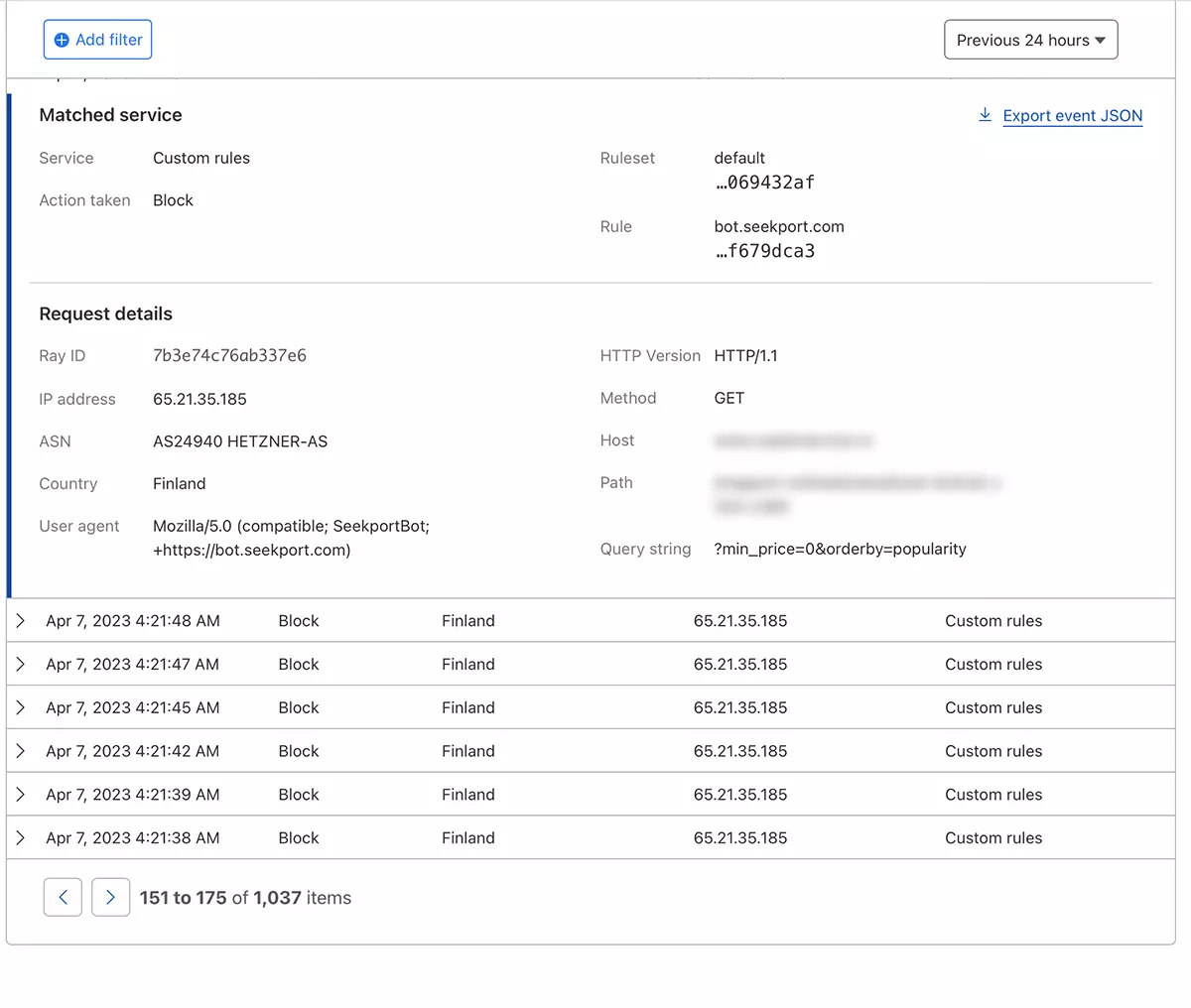
Θεωρητικά, η συχνότητα με την οποία μια αράχνη Ιστού έχει πρόσβαση σε έναν ιστότοπο μπορεί να οριστεί από robots.txt, αλλά... είναι μόνο στη θεωρία.
User-agent: SeekportBot
Crawl-delay: 4Πολλά web crawlerii (εκτός από την Bing και την Google) δεν ακολουθούν αυτούς τους κανόνες.
Συμπερασματικά, εάν προσδιορίσετε έναν ιστό γrawΌποιος έχει υπερβολική πρόσβαση στον ιστότοπό σας, είναι καλύτερο να αποκλείσετε την πρόσβασή του εντελώς. Φυσικά, εάν αυτό το bot δεν είναι από μηχανή αναζήτησης στην οποία σας ενδιαφέρει να είστε παρόντες.