Αυτόματα, η εταιρεία πίσω από αυτό WordPress και Tumblr, βρίσκεται σε συνομιλίες για τη δημιουργία εσόδων από το περιεχόμενο των χρηστών πουλώντας τα δεδομένα του σε εταιρείες τεχνητής νοημοσύνης, συμπεριλαμβανομένων των MidJourney και OpenAI. Αυτά τα δεδομένα από τις πλατφόρμες blogging Tumblr και WordPressΤο .com θα χρησιμοποιηθεί για εκπαίδευση modeτου AI.
Αν και οι λεπτομέρειες της συναλλαγής είναι ακόμη ασαφείς, η είδηση έχει προκαλέσει ανησυχίες στους χρήστες σχετικά με την πιθανή κατάχρηση του ιδιωτικού περιεχομένου τους στις δύο πλατφόρμες ιστολογίων. Το 404 Media προτείνει επίσης ότι προέκυψαν εσωτερικές διενέξεις στο Automattic επειδή το περιεχόμενο που συλλέχθηκε περιελάμβανε προσωπικά δεδομένα που δεν προοριζόταν να διατηρηθούν στην εταιρεία.
Σε απάντηση στις αντιδράσεις, η Automattic πρόκειται να εισαγάγει μια νέα δυνατότητα που θα επιτρέπει στους χρήστες να εξαιρεθούν από την κοινή χρήση των δεδομένων τους για εκπαίδευση τεχνητής νοημοσύνης. Η εταιρεία, σε μια ανάρτηση ιστολογίου, επιβεβαιώνει τη δέσμευσή της να παρέχει στους χρήστες του Tumblr και WordPress μεγαλύτερο έλεγχο του περιεχομένου τους. Αναφέρει την έναρξη μιας ρύθμισης για την «αποθάρρυνση της εξερεύνησης από εταιρείες τεχνητής νοημοσύνης», εξηγώντας ότι οι κορυφαίες πλατφόρμες εξερεύνησης τεχνητής νοημοσύνης είναι αποκλεισμένες από προεπιλογή.
Το πρόβλημα χρήσης περιεχομένου από ιστολόγια από εταιρείες που αναπτύσσουν modele AI, δεν περιορίζεται μόνο στις πλατφόρμες που διαχειρίζεται η εταιρεία Automattic. τόσο πολύ OpenAI όπως η Google, χρησιμοποιήστε c-botsrawler με το οποίο συλλέγω πληροφορίες από όλους τους ιστότοπους, για να εκπαιδεύσω modeτεχνητή νοημοσύνη leles. Η διαδικασία είναι παρόμοια με τη συλλογή δεδομένων από τις μηχανές αναζήτησης.
Πώς μπορείτε να μπλοκάρετε OpenAI και ο Δίδυμος (Bard) παίρνει τα δεδομένα από το ιστολόγιό σας;
Εάν είστε ιδιοκτήτης ιστολογίου ή ιστότοπου και δεν θέλετε τα δεδομένα από αυτό να χρησιμοποιηθούν για εκπαίδευση modeτης τεχνητής νοημοσύνης OpenAI και Gemini, μπορείτε να αποκλείσετε τα bots (γrawlers) στο περιεχόμενο. Αυτός ο περιορισμός μπορεί να οριστεί μέσω του αρχείου robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
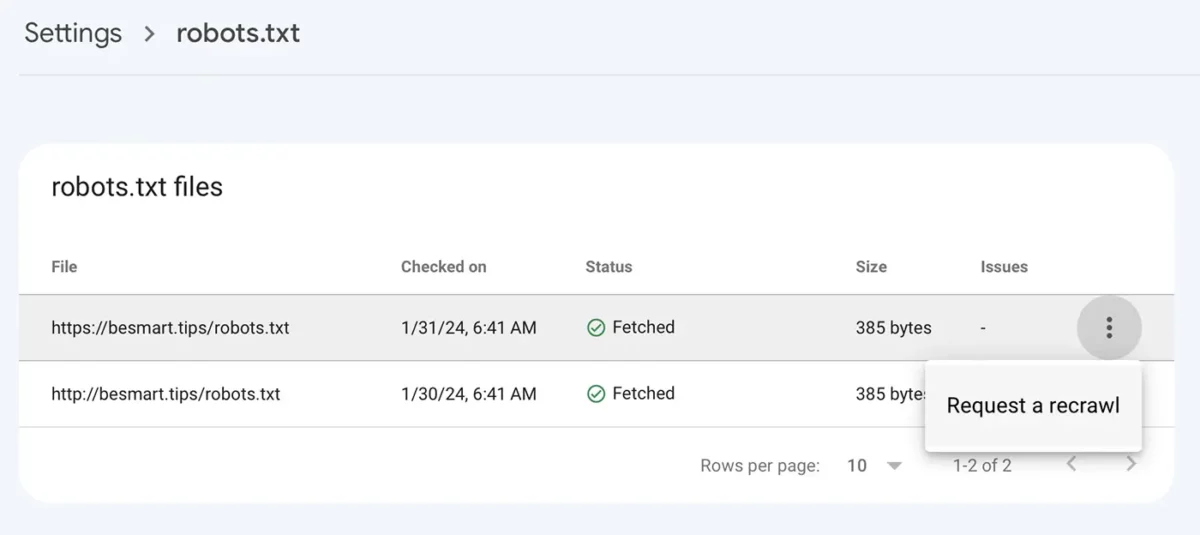
Disallow: /Αφού αποθηκεύσετε το αρχείο robots.txt με τις νέες γραμμές, μεταβείτε στην Κονσόλα Google για να: Settings > robots.txt > κάντε κλικ στο μενού με τις τρεις τελείες, κάντε κλικ στο "Request a recrawl".
Συγγενεύων: Το GPT-5 και το νέο web crawler GPTBot που αναπτύχθηκε από την OpenAI.
Για χρήστες Tumblr και WordPress, την πρόσβαση στην ανάκτηση δεδομένων από ιστολόγια από OpenAI ή άλλες εταιρείες ανάπτυξης τεχνητής νοημοσύνης, θα μπορούν να αποκλειστούν μέσω των εργαλείων που διαθέτει η εταιρεία Automattic.